C语言基础之内存分配
1 | // main.c |
1. 存储时内存结构
下面列出C语言可执行程序的基本情况(Linux/Gcc):1
2
3
4
5
6
7
8
9$ file test
test: ELF 64-bit LSB executable, x86-64, version 1 (SYSV),
dynamically linked (uses shared libs), for GNU/Linux 2.6.32,
BuildID[sha1]=0x707bb98b5c2af90d210b5826cb3e7b8c7fe0e384,
not stripped
$ cc main.c -o test
$ size test
text data bss dec hex filename
1802 576 24 2402 962 test
可以看出,此可执行程序在存储时(没有调入到内存)分为代码区(text)、数据区(data)和未初始化数据区(bss)3个部分。
- 代码区(text)
存放CPU执行的机器指令。通常,代码区是可共享的(即另外的执行程序可以调用它),因为对于频繁被执行的程序,只需要在内存中有一份代码即可。代码区通常是只读的,使其只读的原因是防止程序意外地修改了它的指令。另外,代码区还规划了局部变量的相关信息。 - 数据区(data)
该区包含了在程序中明确被初始化的全局变量、静态变量(包括全局静态变量和局部静态变量)和常量数据(如字符串常量)。 - 未初始化数据区(bss)
存入的是全局未初始化变量。BSS这个叫法是根据一个早期的汇编运算符而来,这个汇编运算符标志着一个块的开始。BSS区的数据在程序开始执行之前被内核初始化为0或者空指针(NULL)。
2. 运行时内存分布
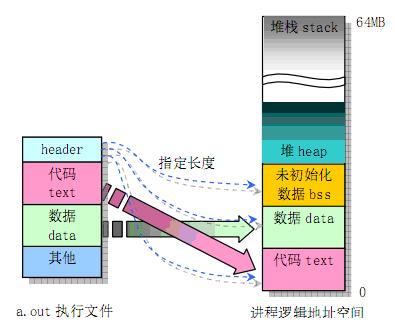
上图所示为可执行代码存储时结构和运行时结构的对照图。
1 | $ ./test |
一个正在运行着的C程序占用的内存分为代码区、初始化数据区、未初始化数据区、堆区和栈区5个部分。
- 栈区(stack)
由编译器自动分配释放,存放函数的参数值、局部变量的值等。其操作方式类似于数据结构中的栈。每当一个函数被调用,该函数返回地址和一些关于调用的信息,比如某些寄存器的内容,被存储到栈区。然后这个被调用的函数再为它的自动变量和临时变量在栈区上分配空间,这就是C实现函数递归调用的方法。每执行一次递归函数调用,一个新的栈框架就会被使用,这样这个新实例栈里的变量就不会和该函数的另一个实例栈里面的变量混淆 - 堆区(heap)
用于动态内存分配。堆在内存中位于bss区和栈区之间。一般由程序员分配和释放,若程序员不释放,程序结束时有可能由OS回收。
3. 程序分区的原因
- 一个进程在运行过程中,代码是根据流程依次执行的,只需要访问一次,当然跳转和递归有可能使代码执行多次,而数据一般都需要访问多次,因此单独开辟空间以方便访问和节约空间。
- 临时数据及需要再次使用的代码在运行时放入栈区中,生命周期短。
- 全局数据和静态数据有可能在整个程序执行过程中都需要访问,因此单独存储管理。
- 堆区由用户自由分配,以便管理。
4. 内存分配方式
在C语言中,可以使用静态或动态的方式分配内存空间。
- 静态分配:编译器在处理程序源代码时分配
- 动态分配:程序在执行时调用malloc库函数申请分配
静态与动态内存分配的主要区别如下:
- 静态内存分配是在程序执行之前进行的因而效率比较高,而动态内存分配则可以灵活的处理未知数目的。
- 静态对象是有名字的变量,可以直接对其进行操作;动态对象是没有名字的变量,需要通过指针间接地对它进行操作。
- 静态对象的分配与释放由编译器自动处理;动态对象的分配与释放必须由程序员显式地管理,它通过malloc()和free两个函数(C++中为new和delete运算符)来完成。